Before considering what happens when we log a sample, we shall digress for a moment and look at the general structure of the data collection system.
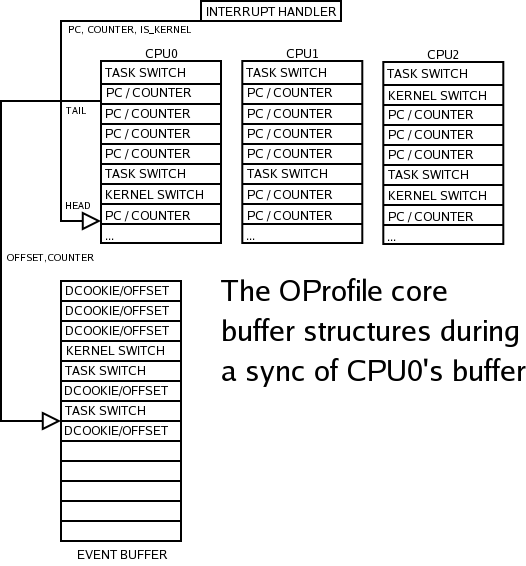
OProfile maintains a small buffer for storing the logged samples for each CPU on the system. Only this buffer is altered when we actually log a sample (remember, we may still be in an NMI context, so no locking is possible). The buffer is managed by a two-handed system; the "head" iterator dictates where the next sample data should be placed in the buffer. Of course, overflow of the buffer is possible, in which case the sample is discarded.
It is critical to remember that at this point, the PC value is an absolute value, and is therefore only meaningful in the context of which task it was logged against. Thus, these per-CPU buffers also maintain details of which task each logged sample is for, as described in the next section. In addition, we store whether the sample was in kernel space or user space (on some architectures and configurations, the address space is not sub-divided neatly at a specific PC value, so we must store this information).
As well as these small per-CPU buffers, we have a considerably larger single buffer. This holds the data that is eventually copied out into the OProfile daemon. On certain system events, the per-CPU buffers are processed and entered (in mutated form) into the main buffer, known in the source as the "event buffer". The "tail" iterator indicates the point from which the CPU may be read, up to the position of the "head" iterator. This provides an entirely lock-free method for extracting data from the CPU buffers. This process is described in detail later in this chapter.